I’m always obsessed with maximizing computing performance despite not being on the latest and thus “best” computers; other than my wife’s M1 MacBook Air, I’m still an Intel holdout, with a Trashcan Mac Pro acting as a home server, a headless iMac Pro and my own “work” iMac Pro (both 8-cores, bought together as secondhand for cheap), and my main mobile work computer, the 2019 top spec (CPU and GPU) 16 inch MacBook Pro.
Since I hoard all family photos and videos, there’s always a need to compress videos to smaller file sizes to fit my shared iCloud account (I’m on the 2 TB tier). When re-compressing, the default method is to just use Apple Compressor then the slow, auto-bitrate H.265 setting; it’s easy, in that color profiles/gamut/resolution/frame rate/compatibility are done automatically. One known thing about Apple’s H.265 codec is that it doesn’t beat x265’s ability to get the smallest file sizes and better variable bit rate with visually lossless quality. Apple’s codec, however, is much faster, making it the choice for rapid distribution. But to achieve space savings and not spend on iCloud, x265’s speed is a factor to a certain extent: If you’re encoding on veryslow x265, you’re probably spending a significant amount of that saved iCloud bill on the electricity re-encoding files.
So the aim is to get the best quality, the smallest file size, in the shortest time. And I had a thought: why not use AVX-512. Or the first question: does X.265/ffmpeg use AVX-512?
A look at the x265 documentation also reveals something interesting: despite the research papers produced by Intel, the x265 devs block AVX-512 by default (for likely a multitude of reasons). So I initially tried out AVX-512 by forcing it in ffmpeg:
x265 [info]: HEVC encoder version 4.1+239-8be7dbf81
x265 [info]: build info [Mac OS X][clang 17.0.0][64 bit] 8bit
x265 [info]: using cpu capabilities: MMX2 SSE2Fast LZCNT SSSE3 SSE4.2 AVX FMA3 BMI2 AVX2…and checking the x265 binary directly:
x265 --version
x265 [info]: HEVC encoder version 4.1+1-1d117be
x265 [info]: build info [Mac OS X][clang 16.0.0][64 bit] 8bit+10bit+12bit
x265 [info]: using cpu capabilities: MMX2 SSE2Fast LZCNT SSSE3 SSE4.2 AVX FMA3 BMI2 AVX2As you can see, AVX512 is not listed, despite running it on the iMac Pro.
Let’s grep the default ffmpeg and X.265’s binaries for AVX-512’s distributed via Homebrew (here on my MacBook Pro):
amir@ANAKAYUB-MBP-16-in llama.cpp % which ffmpeg /usr/local/bin/ffmpeg amir@ANAKAYUB-MBP-16-in llama.cpp % objdump -d /usr/local/bin/ffmpeg | grep -E “zmm(1[6-9]|2[0-9]|3[0-1])” | head -n 10 amir@ANAKAYUB-MBP-16-in llama.cpp %Nothing, and ditto for x265.
So I tried seeing if MacOS sees AVX-512 features on capable CPU’s:
sysctl -a | grep machdep.cpu.leaf7_features
machdep.cpu.leaf7_features: ... AVX512F AVX512DQ ... AVX512CD AVX512BW AVX512VL ...As seen here, AVX-512 is supported, as can be referenced even on Apple’s documentations.
Next came a very long journey, aided by Gemini Pro, to try and compile a version of both x265 and ffmpeg that would support AVX-512. Now, I’m a doctor, not a programmer, though I’ve always been a computer nerd.
I initally tried compiling with the correct CMake flags:
cmake ../source \
-DCMAKE_CXX_FLAGS="-march=skylake-avx512 -DENABLE_AVX512=1" \
-DCMAKE_C_FLAGS="-march=skylake-avx512 -DENABLE_AVX512=1" \
-DENABLE_ASSEMBLY=ONBut that led to:
CMake Warning: Manually-specified variables were not used by the project: ENABLE_AVX512What came next was a combination of edits to CMakeLists.txt, common/x86/asm-primitives.cpp, and common/cpu.cpp. Eventually it worked, but I didn’t “backtrack” to see if only 1/2 edits did the job instead of 3.
CMakeLists.txt:
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -1,6 +1,8 @@
project(x265)
+set(ENABLE_AVX512 ON CACHE BOOL "Force AVX512" FORCE)
+add_definitions(-DENABLE_AVX512=1)
include(CheckIncludeFiles)
include(CheckFunctionExists)
include(CheckSymbolExists)
include(CheckCXXCompilerFlag)
include(CheckCSourceCompiles)
include(CheckCXXSourceCompiles)common/x86/asm-primitives.cpp:
--- a/common/x86/asm-primitives.cpp
+++ b/common/x86/asm-primitives.cpp
@@ -345,6 +345,7 @@ void setupAssemblyPrimitives(EncoderPrimitives &p, int cpuMask) // Main10
p.scanPosLast = PFX(scanPosLast_x64);
#endif
+ cpuMask |= X265_CPU_AVX512; // Force AVX-512 enablement
if (cpuMask & X265_CPU_SSE2)
{
p.cu[BLOCK_8x8].sad = PFX(pixel_sad_8x8_sse2);
@@ -742,6 +743,7 @@ void setupAssemblyPrimitives(EncoderPrimitives &p, int cpuMask) // Main
p.scanPosLast = PFX(scanPosLast_x64);
#endif
+ cpuMask |= X265_CPU_AVX512; // Force AVX-512 enablement
if (cpuMask & X265_CPU_SSE2)
{
p.cu[BLOCK_8x8].sad = PFX(pixel_sad_8x8_sse2);common/cpu.cpp:
--- a/common/cpu.cpp
+++ b/common/cpu.cpp
@@ -... +... @@
#if BROKEN_STACK_ALIGNMENT
cpu |= X265_CPU_STACK_MOD4;
#endif
+
+ cpu |= X265_CPU_AVX512; // <--- FORCE ON
return cpu;
}(forgive me if I get the exact diffs wrong. Gemini and Qwen hallucinated, and I rechecked multiple times with corrections, until I gave up)
But things finally worked:
cd ~/x265_git/build_avx512
rm -rf * # Fresh start
cmake ../source \
-DCMAKE_CXX_FLAGS="-march=skylake-avx512 -DENABLE_AVX512=1" \
-DCMAKE_C_FLAGS="-march=skylake-avx512 -DENABLE_AVX512=1" \
-DENABLE_ASSEMBLY=ON
make -j$(sysctl -n hw.ncpu)Followed by:
./x265 —version
x265 [info] build 216 - [GCC 17.0.0] 64-bit
x265 [info] using cpu capabilities: MMX2 SSE2Fast SSSE3 SSE4.2 AVX AVX2 FMA3 BMI2 AVX512
objdump -d /usr/local/bin/ffmpeg | grep -E "zmm(1[6-9]|2[0-9]|3[0-1])" | head -n 10
10048b2f9: 62 a1 75 40 ef c9 vpxord %zmm17, %zmm17, %zmm17
10048b302: 62 e1 7e 48 6f 04 07 vmovdqu32 (%rdi,%rax), %zmm16
10048b309: 62 e1 7d 40 f6 04 02 vpsadbw (%rdx,%rax), %zmm16, %zmm16
10048b310: 62 a1 f5 40 d4 c8 vpaddq %zmm16, %zmm17, %zmm17
10048b32d: 62 e1 7e 48 7f 0f vmovdqu32 %zmm17, (%rdi)
10048b349: 62 a1 75 40 ef c9 vpxord %zmm17, %zmm17, %zmm17
10048b352: 62 e1 7e 48 6f 04 07 vmovdqu32 (%rdi,%rax), %zmm16
10048b359: 62 e1 7d 40 f9 04 02 vpsubw (%rdx,%rax), %zmm16, %zmm16
10048b360: 62 a2 7d 48 1d c0 vpabsw %zmm16, %zmm16
10048b366: 62 e1 7d 40 f5 05 e0 ee 1c 01 vpmaddwd 0x11ceee0(%rip), %zmm16, %zmm16 ## 0x10165a250 <_ff_bwdif_comp_spv_len+0x170c>And checking the x265 bin itself:
x265 --version
x265 [info]: HEVC encoder version 4.1+239-8be7dbf81
x265 [info]: build info [Mac OS X][clang 17.0.0][64 bit] 10bit
x265 [info]: using cpu capabilities: MMX2 SSE2Fast LZCNT SSSE3 SSE4.2 AVX FMA3 BMI2 AVX2 AVX512And when transcoding with explicit instructions to use AVX-512 (with -x265-params “asm=avx512”):x265 [info]: using cpu capabilities: MMX2 SSE2Fast LZCNT SSSE3 SSE4.2 AVX FMA3 BMI2 AVX2 AVX512You can also see this via screenshots of Apple Instruments (And the sight of x265_pixel_sad_x4_64x64_avx512 function calls among others):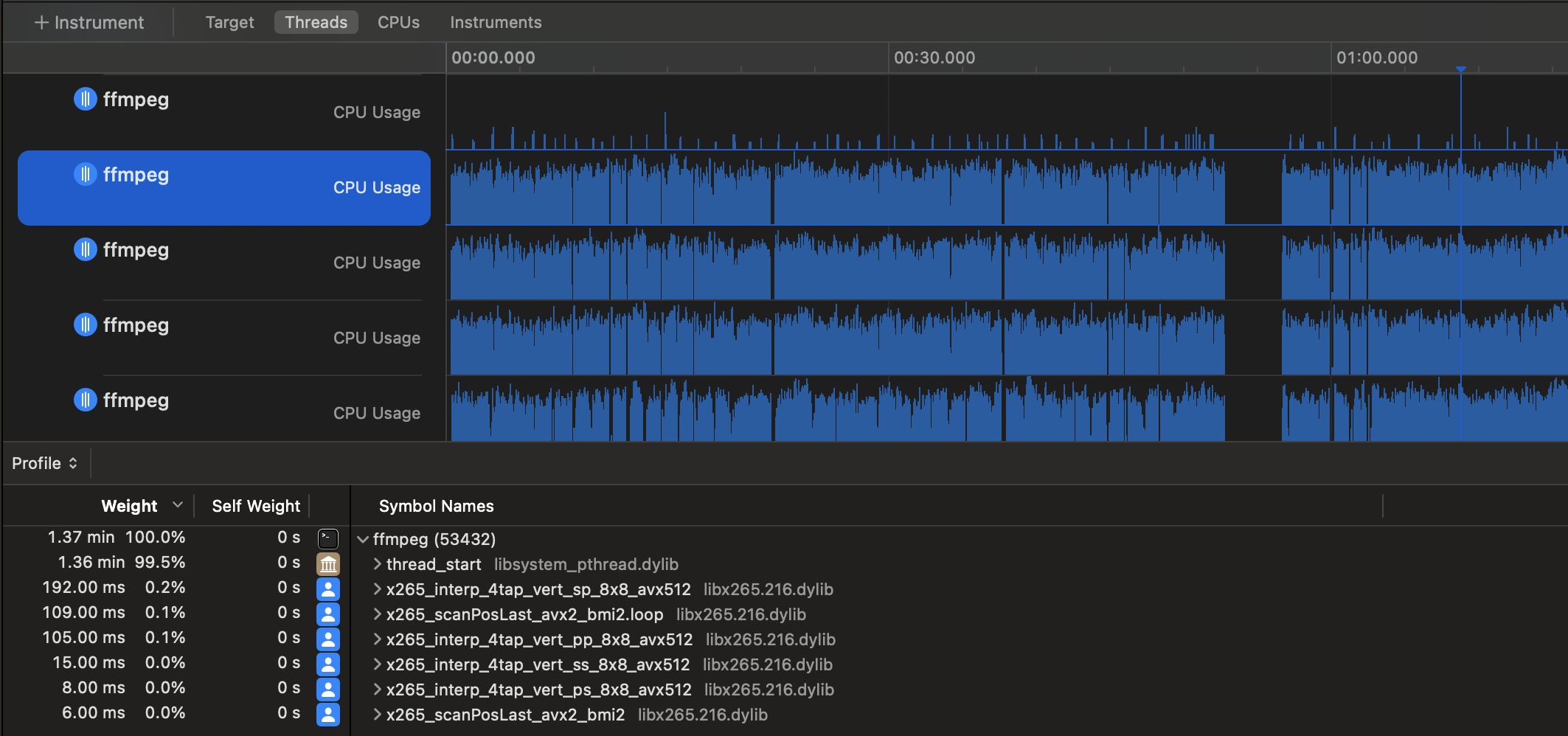
(it’s not the exact function call in this screenshot, but I don’t care. This article took long enough)
Next came a different problem: There wasn’t much of performance improvements, and on some runs, there was even worse performance with AVX-512 vs AVX2.
So then I entered another rabbit hole of optimizations, and the conclusion was this: with increasing computation complexity (from more complex settings), x265 goes very deep into the smallest pixel block analyses, and CPU cycles are all spent there. There was no unnecessary wait states, no memory bottlenecks from what I could tell. Additionally, since x265 then analyzes and encodes based on the smallest (and non-square) blocks with more computationally extensive parameters, smaller SIMD’s (sse2, AVX2, even MMX) are used instead and AVX-512 is less used. Unfortunately, I deleted the screenshots, but examples of the function calls include:
"Square" blocks processed with SIMD's:
x265_pixel_sad_x4_8x8_sse2.loop
x265_pixel_avg_8x8_sse2
x265_pixel_sad_x4_64x64_avx512
x265_pixel_sad_x4_32x32_avx512
x265_pixel_satd_8x8_avx2
x265_interp_8tap_horiz_ps_64x64_avx512.loop"Non-square (rect/amp (?) turned on, using other SIMD's and never AVX-512:
x265_interp_8tap_horiz_ps_4x8_avx2.loopSo to force performance improvements, I needed to force AVX-512 use by avoiding unnecessary x265 parameters. This included changing from veryslow/slower to the slow preset with some modifications to the default parameters. To force “square”-based analysis, both —rect and —amp were turned off. —subme was allowed to remain at level 4 (the default for slow was 3). —rskip of 2 was used to terminate recursions early when acceptable. Once those fine-tunes were done, the next step was fine-tuning the lookahead threads, but this was totally dependent on the source footage. For 4K videos, allocating 4 (SDR) or 6 (HDR) threads maximized performance, but for 1080p, there were not lookahead tests done (4 seemed to be ok with the W-2140B), even though the CPU was not 100% utilized like with higher res videos. But with the 1080p footage, enabling —pmode (to try to improve CPU optmization) did not improve performance, but made it worse.
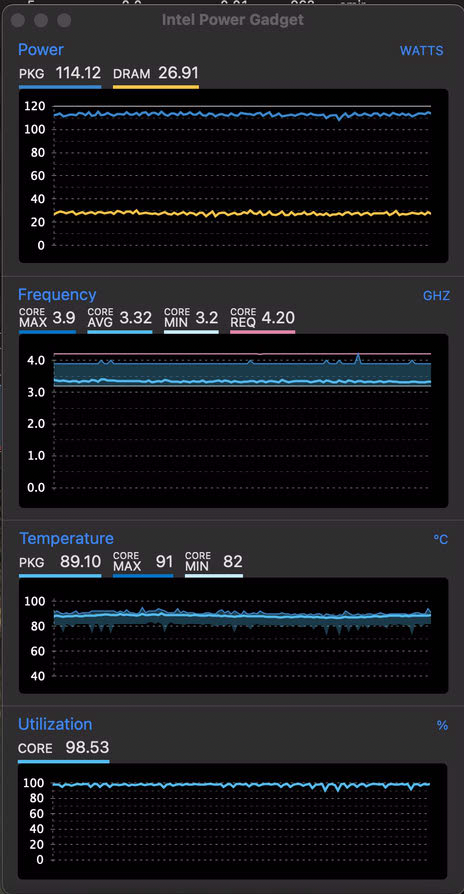
Good CPU utilization with 4K video
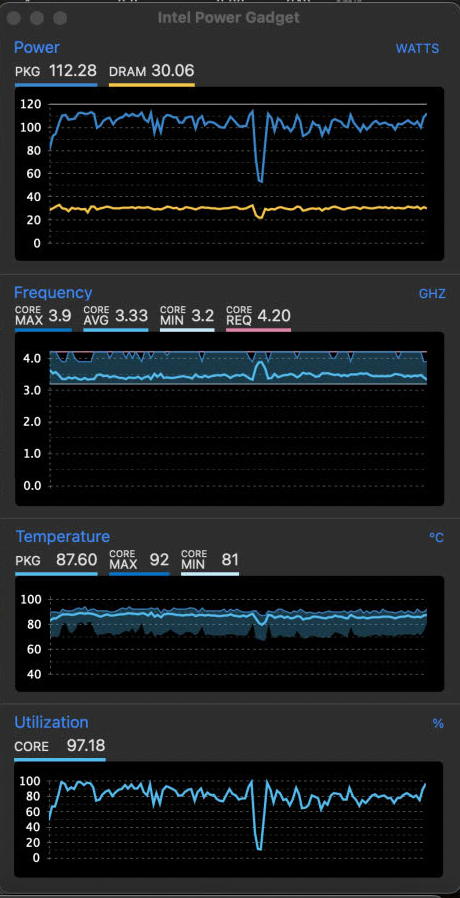
Erratic CPU utilization with lower resolutions
At that point, the only further optimization to me was individual tuning of lookahead-threads (source-dependent). But with the “optimized” settings, AVX-512 consistently beat AVX2. And the output quality (based on AVQT) did not suffer from x265 options that reduced computation (since I guess, AVQT/VMAF scores would depend more on the CRF set vs other parameters, that would determine the compression efficiency).
4K HDR tests:
Segment[0]: AVQT: 4.96
Segment[1]: AVQT: 4.96
Segment[2]: AVQT: 4.98
Segment[3]: AVQT: 4.96
Segment[4]: AVQT: 4.95
Segment[5]: AVQT: 4.97
Segment[6]: AVQT: 4.98
Segment[7]: AVQT: 4.97
Segment[8]: AVQT: 4.98
Segment[9]: AVQT: 4.99
Segment[10]: AVQT: 4.98With all that, how did AVX-512 improve x265’s (and by extension, ffmpeg) performance? To be frank, not by much, and unless if you’re running a render farm with full CPU utilization all the time, the testing I’ve done probably outspent any energy savings from reduced compression times. Even with so called optimization attempts, the gains were as low as 1.55% (1080p, SDR, CRF 22) up to 12.4% (4K SDR). Without trying to show all of the runs, let me just say that statistically, there was about a 5% (+/- 7.57% of 2SD) increase in FPS. With more configurations and testing, I could probably erase the possibility of AVX-512 being slower than AVX2 statistically, but I think that’s enough.
My own conclusions would probably be consistent with those who are truly smarter than me in this realm. If the computation is too much, AVX-512’s downclocking of older CPU’s will hamper its performance running the rest of the code. But even when the settings are optimal, x265 and ffmpeg do not have enough “SIMD-able” instructions to make the use of AVX-512 a massive leap in performance. As a matter of fact, during this “journey”, I even tried out an AVX-512 benchmark (to prove to myself that theoretical improvements do exist on the iMac Pro system if AVX-512 code is used):
#include <iostream>
#include <vector>
#include <chrono>
#include <algorithm>
#include <immintrin.h>
#include <thread>
#include <iomanip>
// ----------------------------------------------------------------
// AVX-512 Implementation (Deep FMA Compute)
// ----------------------------------------------------------------
void avx512_worker(float* data, size_t size, int iterations) {
__m512 c1 = _mm512_set1_ps(1.000001f);
__m512 c2 = _mm512_set1_ps(0.000001f);
for (int iter = 0; iter < iterations; ++iter) {
for (size_t i = 0; i < size; i += 16) {
__m512 v = _mm512_loadu_ps(&data[i]);
// Do 50 Fused Multiply-Adds to saturate the ALUs
for (int j = 0; j < 50; ++j) {
v = _mm512_fmadd_ps(v, c1, c2);
}
_mm512_storeu_ps(&data[i], v);
}
}
}
// ----------------------------------------------------------------
// AVX2 Implementation (Deep FMA Compute)
// ----------------------------------------------------------------
void avx2_worker(float* data, size_t size, int iterations) {
__m256 c1 = _mm256_set1_ps(1.000001f);
__m256 c2 = _mm256_set1_ps(0.000001f);
for (int iter = 0; iter < iterations; ++iter) {
for (size_t i = 0; i < size; i += 8) {
__m256 v = _mm256_loadu_ps(&data[i]);
for (int j = 0; j < 50; ++j) {
v = _mm256_fmadd_ps(v, c1, c2);
}
_mm256_storeu_ps(&data[i], v);
}
}
_mm256_zeroupper();
}
// ----------------------------------------------------------------
// Scalar Implementation (Deep FMA Compute)
// ----------------------------------------------------------------
void scalar_worker(float* data, size_t size, int iterations) {
for (int iter = 0; iter < iterations; ++iter) {
#pragma clang loop vectorize(disable)
#pragma GCC ivdep
for (size_t i = 0; i < size; ++i) {
float v = data[i];
for (int j = 0; j < 50; ++j) {
v = (v * 1.000001f) + 0.000001f;
}
data[i] = v;
}
}
}
// ----------------------------------------------------------------
// Thread Manager
// ----------------------------------------------------------------
template<typename Func>
long long run_multithreaded(Func bench_func, std::vector<float>& data, int num_threads, int iterations) {
std::vector<std::thread> threads;
size_t chunk_size = data.size() / num_threads;
auto start = std::chrono::high_resolution_clock::now();
for (int t = 0; t < num_threads; ++t) {
size_t offset = t * chunk_size;
threads.emplace_back(bench_func, data.data() + offset, chunk_size, iterations);
}
for (auto& thread : threads)
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
}
// ----------------------------------------------------------------
// Main Execution
// ----------------------------------------------------------------
int main() {
// Determine physical cores (assuming Hyper-Threading is 2 logical threads per physical core)
unsigned int logical_cores = std::thread::hardware_concurrency();
unsigned int physical_cores = (logical_cores > 1) ? logical_cores / 2 : 1;
// 128,000 floats = 512 KB per thread. Fits perfectly inside the 1MB L2 cache of a Xeon W core.
const size_t SIZE_PER_THREAD = 128 * 1024;
const size_t TOTAL_SIZE = SIZE_PER_THREAD * physical_cores;
const int ITERATIONS = 2000;
std::cout << "Detected Logical Cores: " << logical_cores << "\n";
std::cout << "Targeting Physical Cores: " << physical_cores << "\n";
std::cout << "Dataset Size: " << (TOTAL_SIZE * sizeof(float)) / 1024 << " KB total ("
<< (SIZE_PER_THREAD * sizeof(float)) / 1024 << " KB per physical core)\n\n";
std::vector<float> data(TOTAL_SIZE);
// --- AVX-512 Test ---
std::fill(data.begin(), data.end(), 1.0f);
std::cout << "Running AVX-512 test on " << physical_cores << " threads..." << std::endl;
auto avx512_time = run_multithreaded(avx512_worker, data, physical_cores, ITERATIONS);
// --- AVX2 Test ---
std::fill(data.begin(), data.end(), 1.0f);
std::cout << "Running AVX2 test on " << physical_cores << " threads..." << std::endl;
auto avx2_time = run_multithreaded(avx2_worker, data, physical_cores, ITERATIONS);
// --- Scalar Test ---
std::fill(data.begin(), data.end(), 1.0f);
std::cout << "Running Scalar test on " << physical_cores << " threads..." << std::endl;
auto scalar_time = run_multithreaded(scalar_worker, data, physical_cores, ITERATIONS);
// --- Output ---
std::cout << "\n=== Results ===" << std::endl;
std::cout << "AVX-512: " << avx512_time << " ms" << std::endl;
std::cout << "AVX2: " << avx2_time << " ms" << std::endl;
std::cout << "Scalar: " << scalar_time << " ms" << std::endl;
if (avx512_time > 0) {
std::cout << std::fixed << std::setprecision(2);
std::cout << "Speedup (AVX-512 vs Scalar): " << (float)scalar_time / avx512_time << "x" << std::endl;
std::cout << "Speedup (AVX-512 vs AVX2): " << (float)avx2_time / avx512_time << "x" << std::endl;
}
return 0;
}
And there was proof of AVX-512 related performance improvements:
amir@Amirs-iMac-Pro ~ % clang++ -O3 -march=native -std=c++17 avx512_mt.cpp -o avx512_mt ./avx512_mt Detected Logical Cores: 16 Targeting Physical Cores: 8 Dataset Size: 4096 KB total (512 KB per physical core) Running AVX-512 test on 8 threads... Running AVX2 test on 8 threads... Running Scalar test on 8 threads... === Results === AVX-512: 425 ms AVX2: 778 ms Scalar: 6052 ms Speedup (AVX-512 vs Scalar): 14.24x Speedup (AVX-512 vs AVX2): 1.83x
So yes, AVX-512 does exist and such SIMD can be run on MacOS on the iMac Pro and 2019 Mac Pro. But no, AVX-512 is probably not the answer to make x265/ffmpeg run much faster. But I could be wrong. Since a 5% rate of complications in medicine is considered very significant, similarly it could be important to geeks if it means that a machine spends 5% less time busy and waiting for the main bottleneck in human computing: user input.